前言
读研这么久,总算开始产出一点科研成果(bushi)。
从写开题报告开始使用zotero阅读文献(ctrl+c, ctrl+v),倒现在又半年多了。科研搞得基本没啥动静,叹气。
然后现在课题又进入广调研、定方案的阶段,看着我导打包发的上百篇参考文献总算有点搞科研的样子吧,叹气。
总得来说也是咂摸到搞科研的一些方法论,其实跟搞工程差不多,也是站在旁人的肩膀上,从学习别人的成果开始,大量阅读、学习、使用和复现,总结提取相关竞品的特点和缺点,然后进行需求分析,提出方案。
当然了,这篇幅是谈文献阅读和组织,那主要是针对于这个过程里面调研和学习的部分。与普通搞工程的不同,很多开源工程或库的提供商都致力于实现可理解性、用户友好性,都进行了高度的文档化。但是搞科研就不同,内容多的是灌水,同时最核心的内容不一定开源,或者开源了也不一定就是所说的效果。毕竟科研讲究的是创新。创新嘛,叹气。
科研垃圾的小小吐槽~
zotero
主流的文献组织管理器。其实也不算深度使用,大概记录一下解决我的痛点问题和相关技巧。
所谓文献就是一堆pdf,原本也就是放在一个个文件夹里。然后不断打包下载,就有了好多个文件夹,每个打开都十几篇论文,头大。
如果是刚开始从头开始看,满满一个文件夹几十篇也有点让人沮丧,太多太乱!尝试的做法是先粗度,然后提取抽象出一些分类和侧重点,将他们分入不同的子文件夹中,然后再根据重心选择一个方向对每篇细读、精读。示例如下:
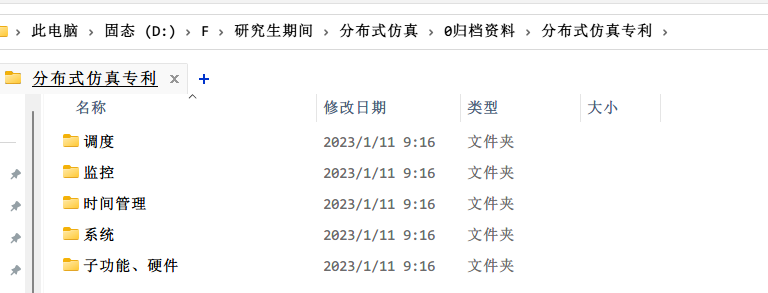
然后阅读的过程就会涉及标注、做笔记和总结。当然了标注和注释这些一般阅读器都会提供,但是就要考虑所标注的这个文件必须要自己保留好、自己完成同步。毕竟论文其实获取都是简便的,但是对论文阅读总结和提取的智慧结晶是宝贵的。然后是对同一篇、同一个子方向的多篇阅读之后,提取核心内容,进行总结。这部分原本的做法是,一边标注,一边对论文内容重新组织,使用原本的概念或者重新抽象一个概念,根据这些概念拷贝论文中核心的内容,总结一个新的文档对阅读过的知识内容进行索引。示例如下:

这个过程的体会来说,完成这个过程对于核心知识的理解、吸收和再索引效果都非常好。唯一的问题是耗时太长,无论是对理解的内容进行抽象和再组织,还是从原文献把内容拷出来(直接拷贝的方法还有可能是内容过长)。同时跟文献也是直接解绑的关系,相互跳转有点麻烦。总结来说,感觉这种方式适合已经看完一个小方向的多篇文献,对已经做好一些抽象、笔记的内容,特别是针对于特别好的文献,进行再组织,最后形成自己理解的知识内容,以后无需再逐一阅读这些论文。
这里就有一个需求,就是即时笔记和总结。
还有就是再索引。刚刚说的这个过程,如果把学习的知识提取到自己的知识库中,那索引就根据自己的知识体系进行即可,基本脱离文献内容。但是像刚刚说的,耗时太长决定了不是所有知识都会被提取出来。一些不是那么实用、或者对当前工作很重要的内容会被暂时搁置。但是以后可能想起这个内容,再想去找出这个知识的原出处就比较麻烦了,甚至直接忘记这个内容。所以对看过的内容,除了即时笔记,还要抽象出标签,帮助以后迅速索引到不同特点、不同方向、不同内容的文献。
以上就是文献阅读和组织的生命周期中的一些需求和相应的方案:
- 分类使得文献体系扁平化,能够迅速专注于某个小问题上。
- 及时笔记和总结让我们只要阅读了就能产出东西。记录万物的哲学。
- 通过标签和抽象实现体系化,方便进行以后的索引。
而上述这个过程就是zotero的核心理念(我自己理解的):
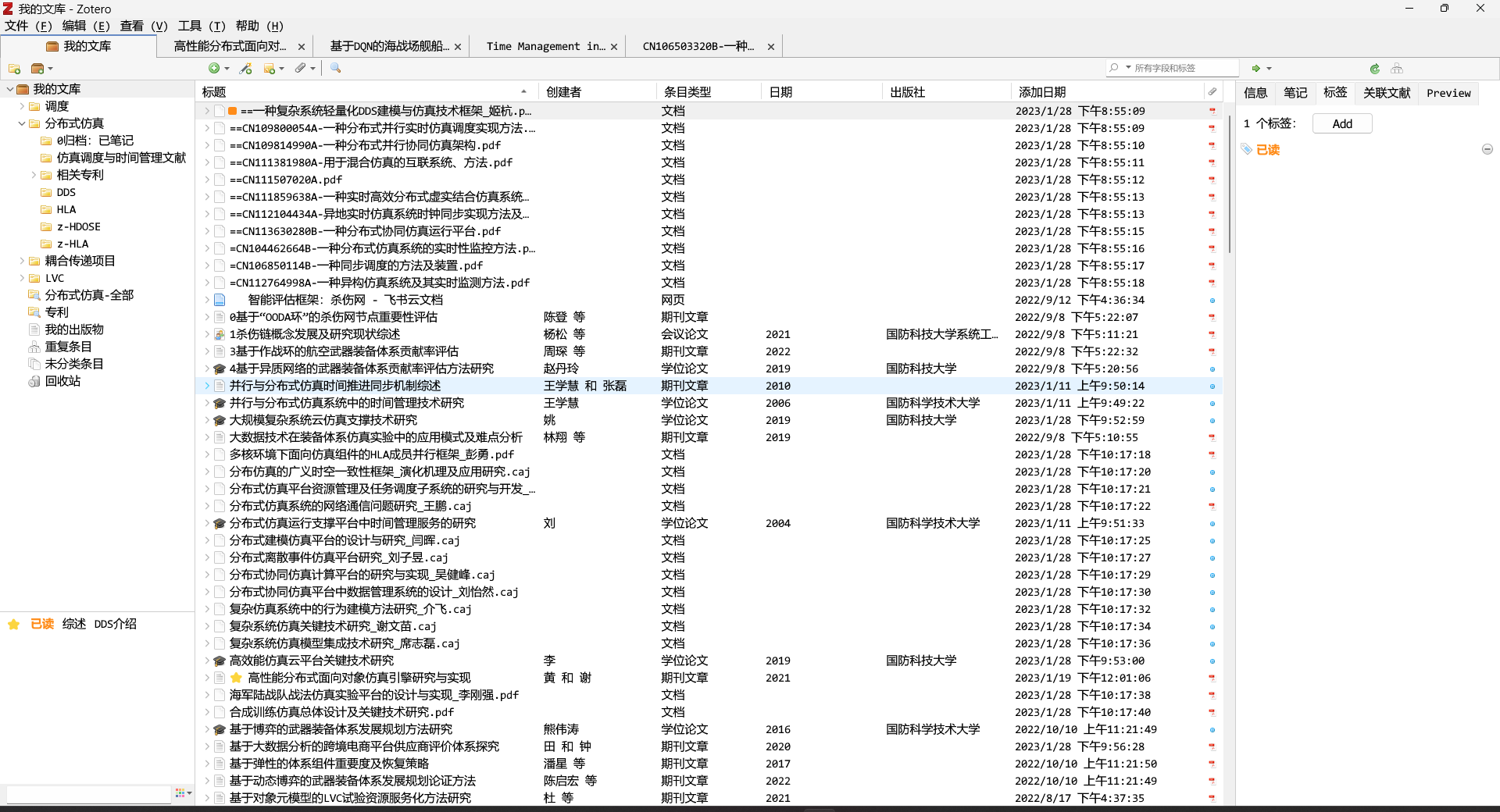
- 所有文献作为一个条目放在文库中,不同条目放入不同的分类中,分类又嵌套包含子分类。另外,一个条目可以放入多种分类,这是合理的,可以有不同的分法。
- 点击一篇文献,右侧显示它的信息、笔记、标签、预览等。对其进行快速评估、索引和查找。
- 论文阅读过程(zotero作为pdf阅读器),可以标注和一边做笔记。
- 右下角直接筛选标签。标签可以使用某种颜色标记。
- 条目和分类的概念跟普通文件夹管理有点不同,一篇文献不会固定在某个地方。所以如果我们想查找的是跨分类的、或者查看该分类下所有条目包括子分类中的(父分类不会直接包含所有子分类条目),那可以使用高级搜索。搜索结果可以保存下来。
结合上述的需求分析和方案,以及zotero使用,目前个人整理的方案如下:
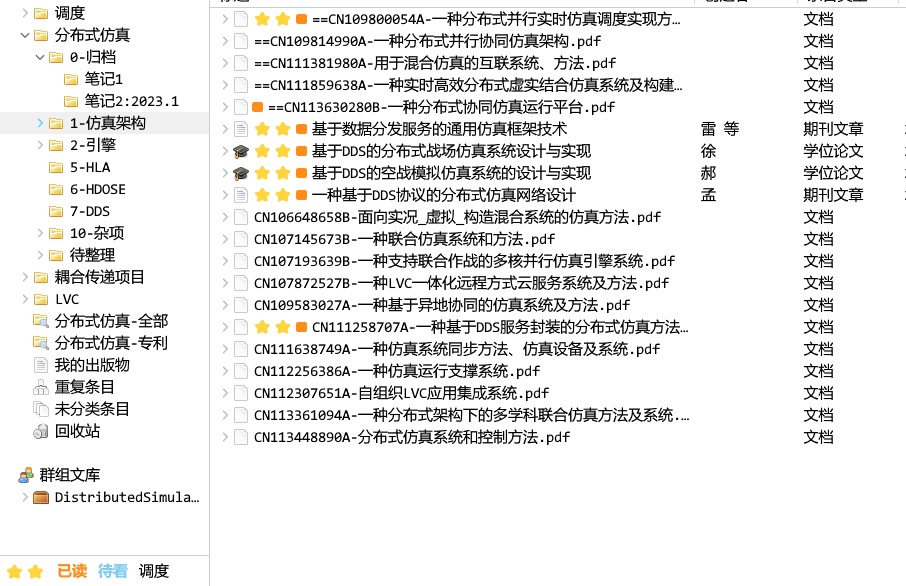
- 首先是分类。将看过(粗看)的文章抽象一个概念放入相应的分类(可以同时放入多个分类)。
- 然后是标签。提炼几个概念:星号标注收藏,标识有参考价值的好论文;已读标注已经看过的论文;待看标注短期的TO DO LIST等。
- 归档标签下,按照时间顺序归类某个时间内看的论文集,最好最终分别产出一篇汇总笔记。
- 固定一个包含该大分类所有文献的高级搜索,就可以对该领域对所有收藏、已看、或其他看完后打上标签的文献进行定向索引。
其他的一些技巧.
插件
有很多很好用的插件,扩展一些小功能。这里我使用的:
- ZotFile:自动重命名和在指定文件夹中关联附件。主要与后者一起把已经打包下载好的文件,导入进来自动构建条目。
- Jasmium:主要是抓取知网元信息。
- Zotero PDF Preview:文献预览。
- Duplcates Merger for zotero:自动去重。
- Zotero PDF Translate:划词翻译。
大部分的下载:Zotero中文社区 (gitee.io)
同步
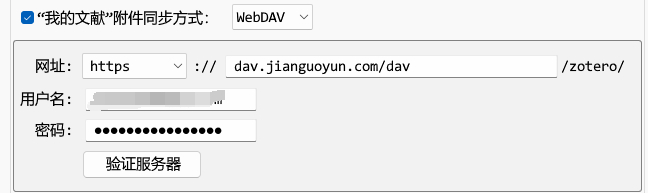
官方提供的同步空间只有300M,文献数量一多就不够用了。目前改为了坚果云(每月1GB的上传流量、单次上传好像也是限制300M左右)。
方式就是在坚果云创建账号,在我的账户中账户安全添加第三方应用,把网址、账户密码复制到zetero中。
共享
研究一个课题往往是一个小组多名成员共同完成。跟做工程类似,调研和阅读文献过程应该也能分工进行团队协作。完全可以在对文献分类后,每个人看其中一个小分类,完成上述的知识提取和再组织过程,然后分发、讲解给团队成员。
如果这样的话,自然产生一个需求:共享同一套文献库的分类、组织和管理,共享笔记和标注,以及最后总结的知识库。
比如上述对文献整理的过程,包括粗读、抽象概念和分类等,这些过程对同一批文献做的工作都是一样的,自然应该分工不让每个成员都重复一样的工作。
所以:只要打开zotero看到的东西都一样就好办。
方案:这就是群组的概念。zotero中新建一个群组,跳转到web端,选择公开或私密的类型(都建议选择public, Closed Membership),设置一下即可。本地管理与普通文献库类似。
问题:群组管理只能通过官方储存库,即只有300M的储存空间。解决方案要么购买更大的空间(但仅需管理员账户一人购买,其他人即可共享)。要么转为仅数据同步,即文献库的体系结构(这部分无上限),而文件同步,即文献PDF等,通过其他第三方同步工具进行(然而安全、空间大、便捷性高的服务哪个不要付费嘞..)。下面是官方的说法。
