编码-C++
字符串
几个概念:
文件编码:UTF-8、ANSI(GB2312)等;
系统环境对中文的解释:活动代码页
编译器选项:可以指定编译器对源文件的解释编码方式、编译器执行时的解释编码方式。这里就包含集中字符集:
源码字符集(the source character set):源代码文件是使用何种编码字符集保存的。
就是你的源代码文本文件的字符集,如果你手头有NotePad++这样类似的文本编辑器你可以打开看一下你的字符集,或者用Windows记事本另存为的时候也会显示文本格式。要知道,你的源代码文本文件是以二进制的形式躺在硬盘里的,无论中文英文都一样,当你输入一个汉字后保存关闭,这个汉字就是按照你指定的字符集转换成二进制编码保存下去的,当你在以这个格式打开文件时候,就再按照你指定的字符集把二进制转回来。如果两次使用不同的字符集,也就会出现乱码了。
执行字符集(the execution character set):源代码经过编译、链接后的可执行文件是使用何种编码字符集保存的,程序实际执行时,内存中的字符串编码就是执行字符集。
执行字符集是一种编码,用于在所有预处理步骤之后输入到编译阶段的程序文本。 此字符集用于编译代码中任何字符串或字符文字的内部表示。
在C++里 char* str= “我”;执行字符集决定了这行代码在编译器进行编译的时候str存储的字节到底是什么,你可能会说源码字符集不是已经决定了这个”我”的二进制表示了么,没错,但是这个执行字符集就是让你在这里对它再解释一次。比如我源码字符集可能是UTF8的,但是我可以通过执行字符集来让最终ptr存储的是GBK的字节编码。
运行环境编码:操作系统(或者当前控制台环境)用于显示文字的编码字符集。
最终要还原显示这些二进制字节编码的时候,就需要用到它。比如通过printf把前面的str显示到控制台时,这个printf就会按照解析字符集来解析这些字节编码,找到指定字符显示出来。
- 不同编译器的实现差异。
- 输出函数。
下面控制变量,集中讨论前三个变量的case。默认选项为:
- 编译器默认为MSVC-2017
- 系统编码(默认代码页):936
- ANSI编码为:GB2312。
测试代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
char sa[] = "国家"; // 国家的gbk编码为:b9fabcd2;utf编码为:e59bbde5aeb6
char sb[] = u8"国家";
char *p = (char *)sa;
int i = 0;
printf("sizeof(sa) is %d\n", sizeof(sa));
for (; i < sizeof(sa); i++) {
printf("byte: %x\n", p[i]);
}
printf("content start\n");
printf("%s\n", sa);
printf("content end\n");
i = 0;
p = (char *)sb;
printf("sizeof(sb) is %d\n", sizeof(sb));
for (; i < sizeof(sb); i++) {
printf("byte: %x\n", p[i]);
}
printf("content start\n");
printf("%s\n", sb);
printf("content end\n");
qDebug() << "output by qdebug sa: " << sa;
qDebug() << "output by qdebug sb:" << sb;
这里使用的一些编码值。查看编码:Character sets that support Unicode Han Character ‘house, home, residence; family’ (U+5BB6) (fileformat.info)
| 中文 | GBK | UTF8 |
|---|---|---|
| 国 | b9fa | e59bbd |
| 家 | bcd2 | e5aeb6 |
ANSI(GB2312)。输出如下(在936终端)。分析结果:在文件编码、系统默认编码等完全一致时,可以看到直接使用中文字符串即可正常输出(即sa)。且sa在内存中存储的编码方式为系统默认编码ANSI(GB2312)的编码(b9fa)。而添加了u8前缀的字符串,最终在内存保存的编码值就是utf8的编码(e59bbd),而不管使用的字符集是什么。但是输出到终端就是乱码的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
sizeof(sa) is 5 byte: ffffffb9 byte: fffffffa byte: ffffffbc byte: ffffffd2 byte: 0 content start 国家 content end sizeof(sb) is 7 byte: ffffffe5 byte: ffffff9b byte: ffffffbd byte: ffffffe5 byte: ffffffae byte: ffffffb6 byte: 0 content start 鍥藉 content end
输出函数和终端代码页。
然而很奇怪的一点是,即使把输出终端改为65001,u8字符串的输出结果还是乱码。输出结果没变。输出的不知道是什么鬼编码。输出到文件用HEX查看长这个样子:
ef bb bf e9 8d a5 e8 97 89 ee 86 8d 0d 0a。UTF8显示鍥藉. 但是如果使用qDebug()输出,能够正常显示(但要求代码页936)。
1 2 3 4
qDebug() << "output by qdebug" << sa; qDebug() << "output by qdebug" << sb; // 936:????、国家 // 65001:????、鍥藉
猜测:输出函数内部又调用了Windows的API,使用ANSI编码又进行转换,UTF-8编码值强行按ANSI(GB2312)输出到终端就会乱码,无论终端是什么编码。(printf里面改变的编码值)。而Qt的输出API默认输入为utf8编码,作为输入刚好,然后输出到Windows的终端时,自动转化为ANSI编码输出到终端,因此终端页必须为默认的系统代码页(936).总结来说就是:printf要求输入为ANSI编码的、QDebug要求输入为utf8编码的。
进一步测试:通过读写文件API,把字节码写入文件中。测试代码如下:
1 2 3 4 5 6 7
ofstream output("output_sa.txt"); output << sa; output.close(); ofstream output1("output_sb.txt"); output1 << sa; output1.close();
结果为:output_sa为ANSI编码,output_sb为UTF8编码,与内存字节码一致。
UTF-8 without BOM. 输出如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
sizeof(sa) is 7 byte: ffffffe5 byte: ffffff9b byte: ffffffbd byte: ffffffe5 byte: ffffffae byte: ffffffb6 byte: 0 content start 鍥藉 content end sizeof(sb) is 10 byte: ffffffe9 byte: ffffff8d byte: ffffffa5 byte: ffffffe8 byte: ffffff97 byte: ffffff89 byte: ffffffee byte: ffffff86 byte: ffffff8d byte: 0 content start 閸ヨ棄顔 content end output by qdebug sa: 国家 output by qdebug sb: 鍥藉
再对比一下UTF-8 with BOM:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
sizeof(sa) is 5 byte: ffffffb9 byte: fffffffa byte: ffffffbc byte: ffffffd2 byte: 0 content start 国家 content end sizeof(sb) is 7 byte: ffffffe5 byte: ffffff9b byte: ffffffbd byte: ffffffe5 byte: ffffffae byte: ffffffb6 byte: 0 content start 鍥藉 content end output by qdebug sa: ???? output by qdebug sb: 国家
带不带BOM的区别我们知道如下。对于无BOM的utf-8文件,它会当成ANSI来读取,所以对于普通的不含u8的字符串,就是直接把utf-8的
"国家"含有的6字节(e5、9b、bd、e5、ae、b6)读进来,认为是每两字节组成的3个ANSI字符(本质上编码值和2个3字节的utf8编码值一样,实际上也不存在这3个二字节的ANSI字符串)。然后对于带u8的字符串,它把这个字符串当成了3个ANSI字符,并对其进行的转码,试图转为3个utf-8字符(e59b这个不存在的ANSI码转为UTF8码),也就是9字节,这显然是越搞越乱。By default, Visual Studio detects a byte-order mark to determine if the source file is in an encoded Unicode format, for example, UTF-16 or UTF-8. If no byte-order mark is found, it assumes the source file is encoded using the current user code page, ..
而对于带BOM的情况,接受的源文件就是UTF8编码的版本,但是看sa的输出结果,可以知道它是将源编码转为了内部代码页(936)对应的ANSI编码,转为了b9fa编码(能够正常输出)。而对于带u8的版本,就是正常保留了utf8的编码值。
编译器选项:/utf-8、/source-charset:utf-8、/execution-charset:utf-8。
其中/source-charset:utf-8:就是强制设定源代码文件为UTF-8编码。这个针对于UTF-8 without BOM的文件较为好用。支持标准不带BOM。所以UTF-8 without BOM + /source-charset:utf-8 = UTF-8.
/execution-charset:utf-8:就是前面所说的执行字符集,是编译代码后任何字符串或字符文字的内部表示(exe中保存的方式),也是加载到内存中实际的编码方式。指定该方法后,无论源文件是哪种类型,对于带u8和不带u8的字符串内存输出都一样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
sizeof(sa) is 7 byte: ffffffe5 byte: ffffff9b byte: ffffffbd byte: ffffffe5 byte: ffffffae byte: ffffffb6 byte: 0 content start 鍥藉 content end sizeof(sb) is 7 byte: ffffffe5 byte: ffffff9b byte: ffffffbd byte: ffffffe5 byte: ffffffae byte: ffffffb6 byte: 0 content start 鍥藉 content end output by qdebug sa: 国家 output by qdebug sb: 国家
/utf-8:=/source-charset:utf-8 + /execution-charset:utf-8。
总结:
对于测试的”国家“:
| 中文 | GBK | UTF8 |
|---|---|---|
| 国 | b9fa | e59bbd |
| 家 | bcd2 | e5aeb6 |
| 文件编码 | 字符串(内存中) | u8字符串(内存中) |
|---|---|---|
| ANSI | GBK/printf能够输出 | UTF/QDebug能够输出 |
| UTF8-BOM or UTF8+/source-charset:utf-8 | GBK/printf能够输出 | UTF/QDebug能够输出 |
| /execution-charset:utf-8 | UTF8/QDebug能够输出 | UTF8/QDebug能够输出 |
以一个更简单的例子,说明编译器读取处理字符串的流程为:
1
2
3
// utf without bom
char* str= "国";
printf("%s\n",str);
首先这个代码文件的文本中”国”这个汉字是以e59bbd三个字节编码的.
当编译器编译这段代码时,执行字符集默认是GBK,那么编译器要决定str的字节内容,就要把文本里保存的字节内容转为GBK,这里就有个值得注意的问题,既然要转换到GBK,就需要知道从什么格式转换到GBK,MSVC怎么知道源格式呢?方法只有一个就是分析你的源文件有没有有BOM,要是有就按照BOM它就认为原格式就是BOM指定的格式,如果没有BOM他就认为你的源码字符集是Locale关联的。刚才说了我们是用UTF8无BOM格式保存的源文件,所以编译器认为源码文本中的”国”是GBK编码保存的。
那从GBK到GBK,MSVC不会进行任何转换,这里有个小问题,提醒一下,这个代码应该是编译不通过的,因为GBK中汉字是2个字节表示的,而UTF8中是三个字节,所以编译器为了凑数会把”国”字后面的双引号给吃掉,转成了两个GBK汉字编码e59b,bd22(22是引号的UTF8编码),没有引号编译器就会报错,最简单的解决办法就是在在后面在加一个汉字变成偶数个就没问题了。所以最后转换到默认为GBK的执行字符集后(本质上就是最后在内存中的样子、也就是我们printf byte的样子),如果是GBK to GBK,这里就保存为e59bbd(但是会认为这是一个GBK串),如果是UTF8 to GBK,那这里会保存为b9fa(GBK字符串)。
程序运行起来后printf输出到控制台,这时候用到的解析字符集也是GBK的,就会用内存里的e59b,bd22去GBK字符集里找到对应编码的汉字“鍥”(不过好像也没找出来、不知道是不是乱映射的)。这当然就错了。
C2001错误:常亮中有换行符。这个错误就是上面说的文件实际存储编码和编译器读进来时认为的编码有差别。
- 假设UTF8当做GBK读:一个中文UTF8编码3个字节,如果认为是GBK编码,那就读成1个半GBK中文,半个中文只好吃掉这个中文后面一个字符,一般来说就是双引号。就导致该报错。硬解决的话就是用偶数个UTF8中文。
- 假设GBK当做UTF8读:两个GBK中文编码为4个字节,如果认为是UTF8编码,则翻译成一个GBK中文+一个多出来的字节,只好吃掉后面两个字符,一般来说就是双引号+分号。硬解决方法也是强行补够字节数为3的倍数。
- 正确的解决方法:将当前文件编码(无论哪种)与编译器接受的编码匹配上。通过
/source-charset编译选项设置。
总结方案就是:
- 对于Qt的项目:UTF8+/source-charset:utf-8+/execution-charset:utf-8,即UTF8+/utf-8即可。输出都使用qDebug接口,需要用C++接口时,使用QString的toLocal8bit即可。
- 对于普通C++项目:使用UTF8-BOM or UTF8+/source-charset:utf-8即可。或者全部使用默认的ANSI(VS就会默认用系统编码打开你的文件,还没办法设置,如果用VS,还是ANSI吧)。
还有一个跟上述讨论完全不同的思路,将ANSI即系统默认编码改为UTF8编码,默认代码页为65001,更改方式见下面”UTF8标准统一下的问题“章节。这样的话系统每个地方编码都可统一为UTF8编码。
Reference:
- (31条消息) C++中的中文编码 乱码的根源及解决方案_「已注销」的博客-CSDN博客_c++输入中文汉字是乱码:三种编码集。
- C++ 字符编码问题探究和中文乱码的产生 | Micooz (apporz.com):完整的示例探索:文本编码+编译器等对比。但是关于输出乱码的描述有问题,输出导致的乱码无法通过更改编码查看到正确的显示。
- MSVC中C++ UTF8中文编码处理探究 - Esfog - 博客园 (cnblogs.com):一个案例分析,但是最后输出到终端的结果(内存中表示为UTF8编码),printf和cout(至少在VS2017)都是无法正常显示的。即使更改chcp 65001也不行。
- (31条消息) Windows下c++字符编码(二)_0_382的博客-CSDN博客_u8“你好世界”:文件编码+编译器+带不带BOM以及相关解释、变换导致乱码等,但是不够详细。
- /utf-8(将源字符集和执行字符集设置为 UTF-8) | Microsoft Learn:编译选项。
Qt字符串
首先观测一下QString内部的字节码。QString毕竟是一个封装的类,要观测其内部状态一般只能通过暴露出来的接口,而无论是qDebug,或者转换为QByteArray等(如toLatin1、toUtf8、toLocal8Bit、toUcs4)都会经过编码转换。怎么直观观测该类的内部状态呢,使用序列化。而作为Qt基本类型,序列化是实现好了的。测试代码:
1
2
3
4
5
6
7
8
QString str = u8"aa"; // 再替换"国家"
QFile file("qt_test.txt");
file.open(QFile::WriteOnly);
QDataStream ostream(&file);
ostream << str;
file.flush();
file.close();
对比aa(上一行)和国家(下一行)的编码,不难找到规律。前四个字节是固定的,后四个字节代表内部的数据。0061就对应a的字节码(无论哪种编码方式都是61,判断不出来),而56fd对应国的字节码,查找编码表可以发现是UTF16-BE的编码方式。同理5bb6就是对应家。结论:QString内部使用UTF16-BE的编码方式。
1
2
00 00 00 04 00 61 00 61
00 00 00 04 56 fd 5b b6
下面主要是测试一下Qt方面提供的API转换。测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
QString str = u8"国家";
// 测试以下接口:toLatin1、toUtf8、toLocal8Bit、toUcs4
auto latin1 = str.toLatin1();
qDebug() << "toLatin1" << latin1
<< "with size of: " << latin1.size(); // "汉字"不在latin1字符集中,所以结果无意义
auto utf8 = str.toUtf8();
qDebug() << "toUtf8" << utf8 << "with size of: " << (utf8.size()); // 返回utf8编码的一串数字
auto local8bit = str.toLocal8Bit();
qDebug() << "toLocal8Bit" << local8bit << "with size of: "
<< (local8bit.size()); // 返回windows操作系统设置的字符集gb2312的编码
auto ucs4 = str.toUcs4();
qDebug() << "toUcs4" << ucs4
<< "with size of: " << (ucs4.size()); // 返回ucs4编码组成的QVector,一个汉字占用4字节
结果:
1
2
3
4
toLatin1 "??" with size of: 2
toUtf8 "\xE5\x9B\xBD\xE5\xAE\xB6" with size of: 6
toLocal8Bit "\xB9\xFA\xBC\xD2" with size of: 4
toUcs4 QVector(22269, 23478) with size of: 2
结论:
- QString::toUtf8是输出UTF-8编码的字符集
- QString::toLatin1是相当与ASCii码。
- QString::Local8bit是本地操作系统设置的字符集编码,一般为GB2312.查看本地操作系统设置的字符集编码,启动cmd ,输入chcp,
- QString::toUcs4就是Ucs4的编码,用的应该比较少。
Reference:
- (31条消息) qt中的toUtf8, toLatin1, Local8bit, toUcs4_土戈的博客-CSDN博客_qt str.tolatin1().data 与 str.toutf8().data 区别
- (31条消息) C++ | Qt 中文乱码总结【持续更新】_烫青菜的博客-CSDN博客_c++ qt不显示中文
- (31条消息) qt中toLocal8Bit和toUtf8()有什么区别_hebao0的博客-CSDN博客
统一系统编码UTF8-推荐
上节最后说的,将ANSI即系统默认编码改为UTF8编码,默认代码页为65001。这里单独对这种情况进行测试,并对一些特殊问题进行处理。
理论上来说,如果统一系统编码为UTF8,那肯定是完全投入UTF8的怀抱。会带来非常多好处。像C++编码,所有地方所有的默认都是UTF8编码(源码字符集、执行字符集、解析字符集),基本告别乱码问题。这就是标准的好处。同时对于其他语言,像Python等,同样减少很多麻烦。所以,强烈建议!
当然事情都有两面性,肯定会带来一些问题。在这逐一列举并解决一下。
- 使用GBK编码的旧项目、编码不标准的项目的兼容性问题:前面说了VS会使用系统代码页的编码方式加载项目文件(或者MS标准的UTF8-BOM也可以)。那如果更改系统编码为UTF8的话,这些项目在VS基本用不了了。解决方案:没什么好的解决方案,VS似乎就是这么倔,找了半天没找到能改读取编码的方法。碰到这种项目,要么转为用其他IDE,要么就把系统编码转回来再做吧。
- 如果硬要用GBK编码的项目,比如通过Qt Creator使用。首先Qt可以设定项目的默认编码为GBK。其次,要让编译器接收的源文件类型和GBK一直,即指定编译选项:
/source-charset:gb2312。 - 谨慎处理代码中与本地编码关联的部分,如Qt中的Local8Bit接口。如果代码使用了这种接口,那输出的结果在不同系统编码的基础上就可能会不同(特别是改变了系统编码为UTF8)。比如Qt界面如果使用fromLocal8bit的话,在utf8系统是正常显示,如果改为GBK系统,按前面说的,硬编码的字符串在UTF8系统保存为UTF8编码,然后在GBK系统运行时,local8bit编码是GBK编码,一个UTF8编码字节码当做GBK字节码用,肯定就会导致乱码。这里冲突的原因是:软件系统内部默认编码UTF8(/UTF8编译选项或编译成exe的平台编码)和Local8Bit这样的接口依赖于不稳定存在的平台编码,这两个编码冲突。不要使用硬编码+平台依赖接口
编码字符集-转载
刚刚一直用了像UTF-8、GB2312等字符集,再来梳理一下字符集的概念。
原文链接:https://blog.csdn.net/m0_37679095/article/details/83722165
我们知道最早的英文字符采用ascii,因为英文字符很少,因此一个char就够用了。但是由于处理其他语言的需求,8位的char显然不够用,这就要求更多位数的编码。
- GBK和ANSI
在中国,我们的国标是GBK,(准确的说经历了GB2312->GBK->GB18030的发展过程),我们常说的汉字占两个字节也就是来源于此。
微软作为一个世界大厂,采用什么编码呢?微软虽然在语言支持上很上心,不过编码却很混乱,微软的默认编码是ANSI,这是个什么东西呢?这其实就是大杂烩,英文还是ascii,中文是GBK,港澳台使用它们那边的Big5……等等。这些编码并不统一,是非常没有兼容性的。其实ANSI不是一种编码,不过我就这么简单的说了,关于ANSI具体是什么,你可以看看这篇文章:https://www.cnblogs.com/malecrab/p/5300486.html。
由于我们主要还是说中文问题,以下提到ANSI的地方,你应该立即联想到,中文是采用GBK编码的。其中,值得一提的是GBK编码是双字节的,这是中文字符占两个字节说法的由来。
- Unicode
由于各地编码的不统一,于是产生了Unicode,Unicode其实是一个标准,而不是一种编码。Unicode现有两套标准,ucs2和ucs4,一开始认为双字节够用,就是ucs2,后来发现双字节不够用,那就扩展到4字节吧,于是就有了ucs4。Unicode现在主要有三种实现方式。即utf-8,utf-16,和utf-32。
- utf-16
先讲utf-16,这是采用双字节表示的,遵从ucs2。在存储时,按两个字节的排布顺序,可以分为UTF-16LE(Little Endian,小端字节序)和UTF-16BE(Big Endian,大端字节序),微软所说的Unicode默认就是 UTF-16LE。注意微软后来也搞了Unicode,但是微软自己鼓吹的Unicode只是其中一种实现方式而已。
utf-16后来发现双字节不够用,于是增加了采用一对双字节来表示一个字符,这其中也包括一些生僻汉字,之后我们将会提到具体例子。所以其实标准的utf-16也是变字长的编码,很多人认为utf-16编码是定长编码,这其实是错误的。此外,utf-16不等价于ucs2,可以认为ucs2是定长编码(双字节),而utf-16是ucs2的扩展。
- utf-32
再说utf-32,既然双字节不够用,那就用四字节吧,于是就有了ucs4标准和utf-32实现方式。utf-32所有的字符都采用4个字节,这才是真正的定长编码。utf-32等价于ucs4,utf-32也存在存储顺序的问题。由于utf-32基本没人用,就不详细展开。
不过,我们知道代码源文件还是ascii字符主导。而在网页上,大量的标记都是ascii字符。utf-32要用4字节,utf-16也要2字节,都比最初的ascii长,这显然是非常浪费空间的,更何况网络传输数据越少越好,因此utf-16和utf-32都是不合用的。
- utf-8
utf-8解决了这个问题,utf-8是完全的变长编码,兼容ascii,也就是ascii编码部分保留,其他的字符根据情况有2,3,4字节。其中特别值得注意的是汉字一般是三个字节,也有四个字节的生僻字情况。(如果你拥护utf-8的话,请不要在说汉字占2字节这样的傻话了。)
utf-8是Unix/Linux系统的默认编码,在这些系统上使用char和string,无论输入输出都是使用utf-8,因此一般不必担心编码问题。在这些系统上,string = “你好世界”的size()是12,也就是一个字符三个字节,是没有任何问题的。你编辑c++源代码基本不必担心编码问题。
但是在windows下就很复杂了。windows自带Notepad是默认ANSI编码的。Notepad++和VS Code是默认utf-8编码,未经配置的gvim以及visual studio默认也是ANSI。关于c++源代码写中文的注意事项,将在之后的文章中详细说明。
总结
现在我们来总结一下编码我们提到的编码知识:
Unicode是编码规范而不是编码方式,它有两个标准,主要有三种实现方式。
utf-8和utf-16都是变长编码,只有utf-32是定长编码。
网页上基本采用utf-8作为编码方式,utf-32基本很难用到。
微软系统采用的ANSI默认编码,兼容ascii,其中文采用GBK编码,汉字为双字节,兼容性不好。
微软也有Unicode,它使用的Unicode是utf-16,不兼容ascii,中文为双字节,少数为4字节。
Unix/Linux采用utf-8变长编码,兼容ascii,其中中文一般为3字节,少数4字节。
建议
现在我们来讨论c++的字符编码问题。
在Unix/Linux系统下,我建议一律采用utf-8编码,一般没有任何问题。不过值得注意的一点是此系统下,wchat_t和wstring表示的字符是4字节的字符,应该就是utf-32了。然而utf-32除了定长这一特点之外,没有任何好处,太浪费空间,用处很少,没必要去碰它。不过wstring的问题我们之后还会讨论,你将会了解更多。
在Windows下,如果你不得不在源文件写中文,而且又不想看我之后几篇又臭又长的详解,你可以使用Qt专有的QString,或者使用Visual Studio来写代码。前者的的默认编码是utf-16,如果不用生僻字,甚至可以按照定长编码的方式处理字符。后者是依靠微软这个IDE强大的功能,可以处理各种编码的源文件。
更多关于UTF-8等编码:
查阅编码表:
UCS2:http://www.columbia.edu/kermit/ucs2.html
各种字符集编码:https://www.fileformat.info/info/unicode/char/6c49/charset_support.htm
宽字节
这部分感觉不常用也没必要用。暂且不管了。
参考:(31条消息) c/c++语言printf/wprintf,wchar_t中文字符输出总结_xiayuleWA的博客-CSDN博客_wprintf和printf
Windows平台的中文编码总结
设置系统编码为UTF8!
中文路径问题继续总结一下:
首先中不中文的没有区别,主要看调用的接口接受什么类型的编码方式,如果接受的编码方式中编码范围包含中文(如UTF8、GBK)那只要按照要求的编码方式输入即可。这个时候,因为涉及路径和文件,一般的接口最终应该都会使用平台相关的接口,比如Windows API,那这个时候接口很可能是依赖于系统默认编码方式的。所以最好转为系统编码方式,比如Qt的toLocal8Bit接口。
这里留了一个坑无法理解的,就是Qt编译项目路径不能带中文的问题。系统编码改了UTF8也不行。看了QMake源码全称用的是fromLocal8Bit也不行,很疑惑。核心错误代码如下。但是神TM用toLatin1转了却能输出出来。==暂时留着这个坑下次编译一下qt源码再验证一下。==
1 2 3 4 5 6 7
QString fn = Option::normalizePath(*pfile); if(!QFile::exists(fn)) { fprintf(stderr, "Cannot find file: %s.\n", QDir::toNativeSeparators(fn).toLatin1().constData()); exit_val = 2; continue; }
1 2
qmake E:\中文\Lee\GenerateLicense.pro Cannot find file: E:\中文\Lee\GenerateLicense.pro.
项目经验
Qt 项目+外部GBK编码项目:统一编码
先说结论:**建议Qt项目默认编码方式为UTF-8编码**,如果外部项目为其他编码方案可以手动选择编码.
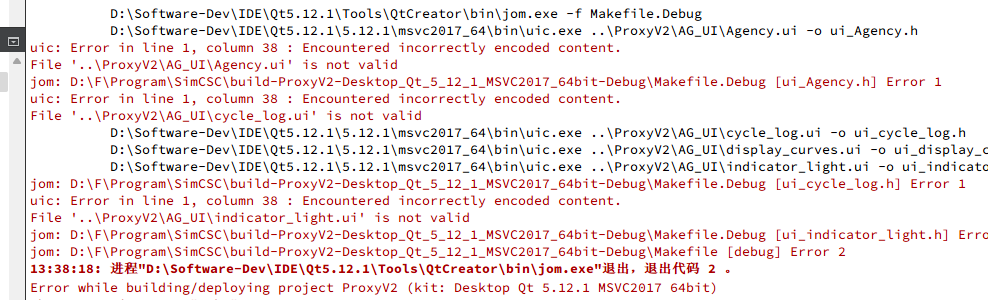
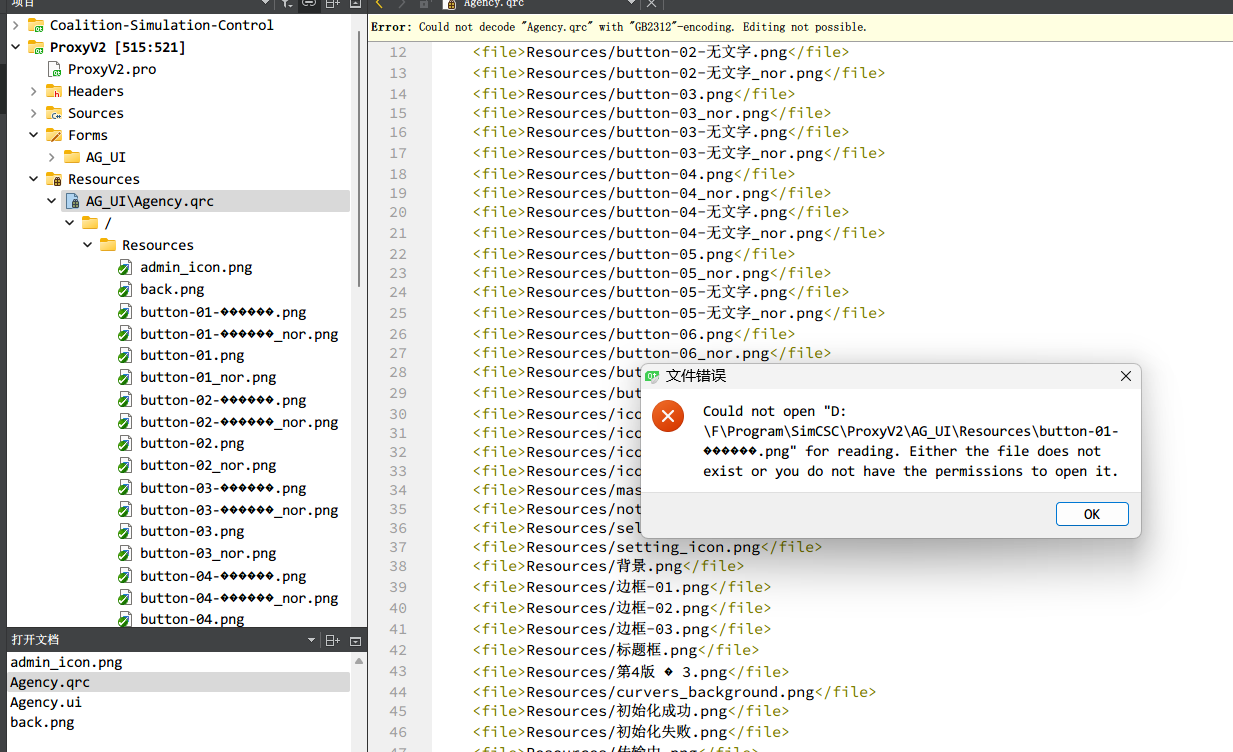
研究过程:UTF8 Or GB2312
如果用GB2312,Qt特有的一些文件,如.ui、.qrc等对非utf8的不能支持(类似于.py),uic编译ui时,要求ui文件时utf8格式。如下图1。同时qrc也要求utf8。在qrc添加资源文件时,会保存为utf8格式。可以强行更改qrc文件编码,但会导致带中文的资源文件乱码,无法加载。如下图2。同时,在Qt Creator中,如果设置默认编码为GB2312,那新建文件时,保存都会保存为GB2312编码(如果包含中文字符),包括UI文件。结合上面的问题,新建的qt文件(UI文件)就必须手动设置为utf8。同时,Qt中打开UTF8编码的UI文件也会提示错误。如下图3(仔细看UI文件头,已经写了
enconding=utf-8,跟GB编码肯定是冲突的)。![output]()

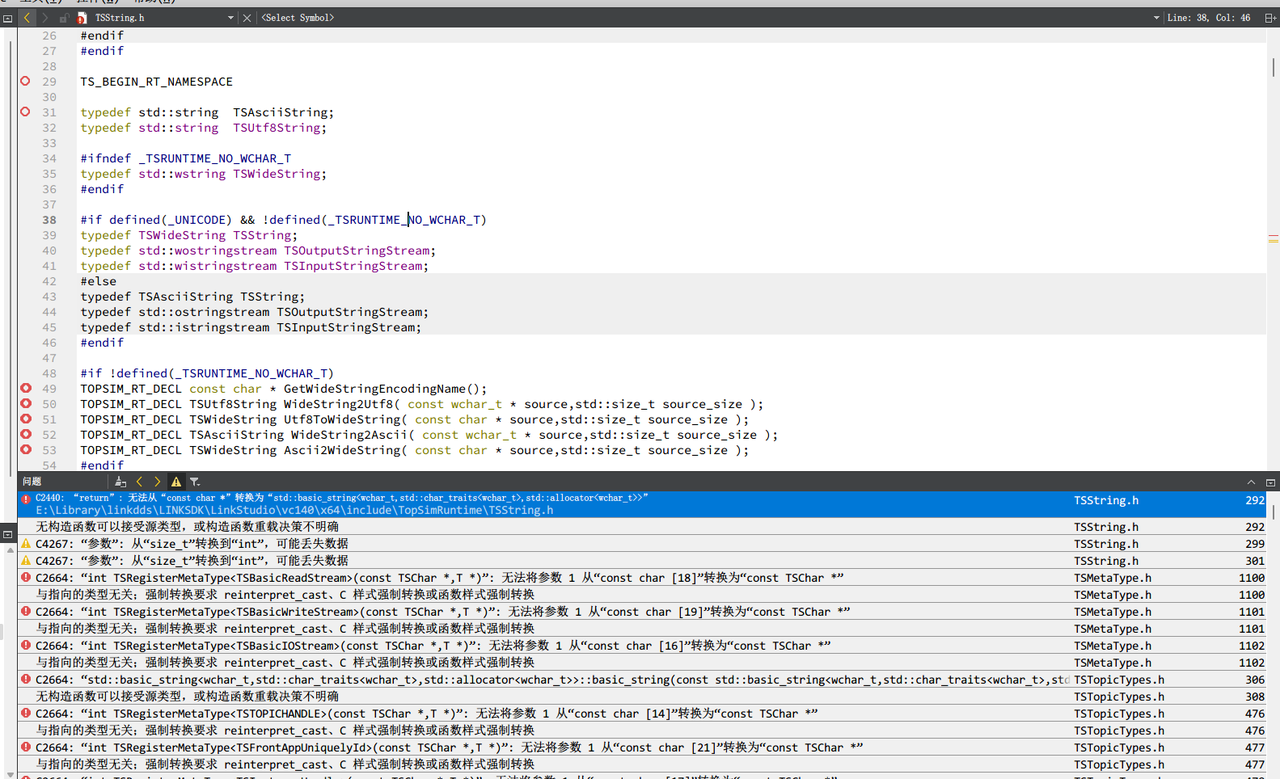
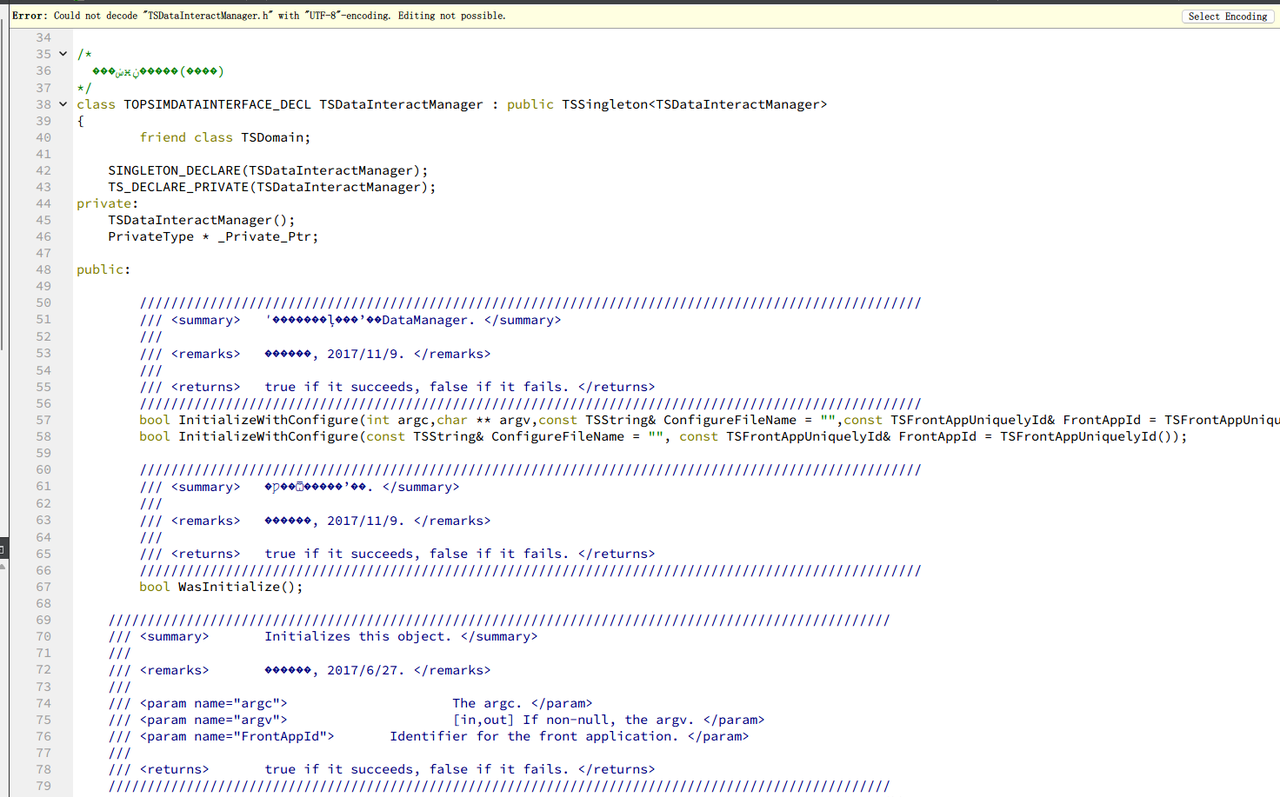
如果统一使用UTF8编码,在我们项目内部完全没有问题(规范编码带来的好处)。问题是与其他项目对接、历史遗留部分存在问题。比如与LinkDDS库的对接。会定义UNICODE的宏,导致字符串转换的错误(主要是对宽字符的处理,它会直接将const char *转换为wstring,语法错误)。如下图1所示。解决方案是可以在项目中手动去掉UNICODE宏(意思是文件,特别是带中文字符的文件是unicode编码,但是告诉编译器说这不是unicode编码)。同时,也会导致在Qt Creator中索引LinkDDS这样用GB2312编码的项目时,中文注释全部乱码,如下图2所示。还有一些导入库编码跟当前项目编码不一致导致的小问题,会给出一些奇怪的报错提示,虽然还是可以运行(在Qt Creator中)。如下图3.
![316c47be-63b2-42f3-8955-f98a9007d202]()
![a39f7c41-8172-4291-86a2-a1adecdb9ecb]()
![3f0765eb-2a57-49bc-b2cf-a8c102c03cee]()

总结:
- GB2312
- 对Qt的文件,如.ui、.qrc等,特指包含中文字符(没有中文字符,GB和U8没有区别)时,用GB2312编码储存不支持。
- 要手动将这些文件设置为utf8,但是设置以后在QtCreator中又不能直接打开。
- 解决:统一用GB2312,Qt相关的用UTF8。Qt相关的(UI)中尽量不包含中文。有中文可以用外部的Qt Designer打开。
- UTF8(目前选择)
- LinkDDS库的对接。会定义UNICODE的宏,导致字符串转换的错误(主要是对宽字符的处理)。
- 索引GB2312编码的项目时,中文注释全部乱码。
- 解决:在项目中手动去掉UNICODE宏。看GB2312项目时,手动选择编码方式。
- 部分问题本质原因是Qt Creator使用一种默认编码方案,对项目所有文件统一按照这个编码方式处理,打开、保存,而不是对每个文件内容进行推测编码,虽然也应该统一编码。(虽然几种C++ IDE,VS、Qt Creator、CLion都不能自动推测,只有VSCode可以)
UTF8标准统一下的问题
先总结问题:下面两个问题都是因为系统默认编码方案GBK和我们统一的标准UTF8冲突导致。具体冲突原因一个是文件编码UTF8和MSVC编译实际判断为ASCII编码冲突;另一个是代码遗留问题,Qt中中文字符串使用fromLocal8Bit是依赖于系统本地编码的,和项目编码标准冲突。
如果把开发环境的系统编码改为UTF8,也不会出现下面问题。更改方式为:语言和区域设置中,勾选beta版utf8.
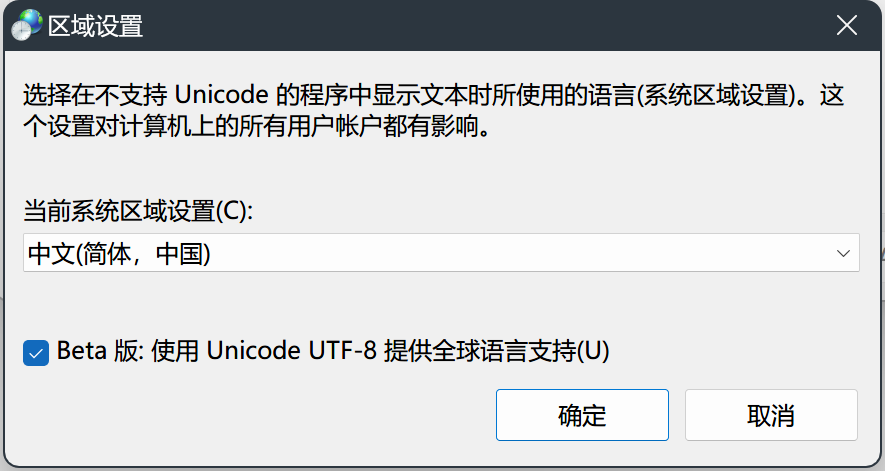
具体问题的研究和解法如下:
- error:常量中有换行符问题
这个问题跟C4819的warning一起出现,区别只是没有用中文字符串的时warning,用中文字符串就是error:
warning: C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失。
原因:虽然warning提示我们使用unicode编码,但这里已经将所有文件统一为uft8编码。所以为什么还会这么提示呢。本质上就是虽然文件是utf8编码(用vscode、notepad++等都能自动识别到),但是msvc不认(就是这么傻逼)。看下解释:意思就是utf8不带bom的话msvc是不认的。Reference.
By default, Visual Studio detects a byte-order mark to determine if the source file is in an encoded Unicode format, for example, UTF-16 or UTF-8. If no byte-order mark is found, it assumes the source file is encoded using the current user code page, …
关于UTF8与UTF8-BOM的对比:https://www.cnblogs.com/flyingeagle/articles/9825302.html
问就是标准就是不带BOM的。怎么办呢。
解决方案:可以设置编译器选项,强制msvc用utf8编译。(注意这个选项并不是Qt Creator那个force utf-8 msvc output,那个只是把编译输出输出到65001代码页的终端)
1
2
3
4
5
msvc {
QMAKE_CFLAGS += /utf-8
QMAKE_CXXFLAGS += /utf-8
QMAKE_CXXFLAGS_WARN_ON += -wd4828 # 与GBK项目的编译警告去除
}
- Qt界面显示乱码。
原因:代码里面通篇用的是QString::fromLocal8Bit("引擎内部句柄转支撑环境句柄发生错误");这样的写法。Local8Bit就是用系统本地编码方案,而windows平台默认肯定是GBK编码。但是我们前面已经规定编译器编码方案用utf8编码。那肯定会导致乱码。
解决:去除所有fromLocal8Bit。代码页里面直接写的中文字符串,直接使用即可。因为已经强制要求使用utf8编码文件了,那里面中文字符串也是utf8编码,qt肯定可以正常显示。
C++ IDE
Visual Studio
Build工具链:好像是MSBuild。不太理解。感觉很复杂,而且项目配置很多东西不像QMake、CMake这么直观,都隐藏在各种UI中,感觉并不好。
编码:这篇博客毕竟是写编码的总结。所以从这个角度都看一下各家IDE对编码的支持情况。首先VS在这方面表现的依托答辩。与系统绑定度极高,基本没有什么灵活性和自由度。就是前面所说的,VS会使用系统代码页的编码方式加载项目文件(或者MS标准的UTF8-BOM也可以)。那如果更改系统编码为UTF8的话,GBK项目在VS基本用不了。同样的,系统编码是GBK时,UTF8不带BOM的项目也基本用不了(会默认用GBK编码打开)。这个基本上是改不了的。不愧是MS自己家的东西,设计是一脉相承的shit。
还有更搞笑的,测试了一下新建项目,在系统编码为GBK时,新建项目的第一个文件是UTF8-BOM编码的,后续新建保存文件默认保存却是GBK编码的。好!
VS Code
编码:自由度最高,每个文件都会猜测编码。毕竟人家就是基于文件,没有原生的项目的概念。
问题:原生只是编辑器,任何事情都要通过插件去做。配置本身虽然不麻烦,但对于即开即用、随手写代码来说是不必要的负担。目前基于C/C++ Runner插件自动配置json启动项目,使用mingw的g++编译器。其他方案还有xmake等。都差不多。
优点:万事都要配置既是缺点也是优点。能够自由、方便地集成各种插件。比如Github Copilot Lab等,支持度最高。
Qt Creator
Build工具链:QMake+jom(基于nmake)
Code Model:Clang
编码:能够设定项目的默认编码方式。在项目->编辑器->更改全局设置为自定义设置。
问题:
- 对编码不一致出现一些奇怪的报错,虽然不影响编译。
- Clang编写经常卡死。
Clion
Build工具链:CMake+ninja,最主流的跨平台方案。
Ninja 是一个跨平台的构建系统,用 C 编写,旨在具有低级别的构建系统功能,适用于大型项目。它用于构建 C,C++ 和 Fortran 项目。它旨在快速高效,可以用于在 Windows,Linux 和 macOS 上构建项目。它也可以扩展,允许用户定义自定义构建规则和命令。
编码:默认猜测为UTF8编码。